
- 本文是 MNIST 擴散模型實作的進階續集——從 28×28 灰階升級到 32×32 RGB 彩色,挑戰真正的自然影像生成
- 引入 5 項現代擴散模型技術:Cosine Noise Schedule[2]、Self-Attention[5]、GroupNorm[6]、EMA、梯度裁剪——每一項都是從玩具模型走向生產級模型的關鍵升級
- 完整實作條件生成 + Classifier-Free Guidance[3],200 epochs 訓練後可生成飛機、汽車、鳥等 10 類彩色物件圖像
- 附可下載 Jupyter Notebook,支援 Google Colab 一鍵運行
前情提要:為什麼要從 MNIST 升級?
如果你已經跟著上一篇 MNIST 實作走過一遍,恭喜——你已經掌握了擴散模型的核心流程。但老實說,MNIST 是個太友善的資料集:只有灰階、28×28 像素、筆劃簡單。用 2.17M 參數的 U-Net 訓練 10 個 epoch 就能搞定,某種程度上就像在駕訓班練車——真正上路後,複雜度完全是另一個層級。
CIFAR-10 就是那條真正的馬路:32×32 彩色圖片,10 個類別涵蓋飛機、汽車、鳥、貓、鹿、狗、青蛙、馬、船、卡車。雖然解析度不高,但三通道的色彩資訊和多樣的物件結構讓它比 MNIST 難了一個數量級。
為了應對這個挑戰,我們需要一系列升級:
| 項目 | MNIST(上一篇) | CIFAR-10(本篇) |
|---|---|---|
| 圖片 | 28×28 灰階 | 32×32 RGB 彩色 |
| Noise Schedule | Linear | Cosine[2] |
| Normalization | BatchNorm | GroupNorm[6] |
| 激活函數 | ReLU | SiLU (Swish) |
| Self-Attention | 無 | 有(16×16 解析度) |
| 殘差連接 | 無 | 有 |
| EMA | 無 | 有(decay=0.9999) |
| 學習率排程 | 固定 1e-3 | Cosine Annealing 3e-4→1e-5 |
| 梯度裁剪 | 無 | 有(max_norm=1.0) |
| 訓練量 | 10 epochs | 200 epochs |
這些升級每一項都有其道理——接下來我們逐步拆解。
Step 1:環境設定 & 載入 CIFAR-10
1.1 匯入套件 & 超參數
和 MNIST 版本幾乎相同的開場,差別在於:圖片變成 3 通道、epochs 拉到 200、學習率降到 3e-4。
import math, time, torch, torchvision
import matplotlib.pyplot as plt
from torchvision import transforms
from torch.utils.data import DataLoader
from torch.optim import Adam
import torch.nn.functional as F
from torch import nn
from tqdm import tqdm
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# ★ 超參數 ★
img_size = 32 # CIFAR-10: 32×32
img_channels = 3 # RGB 彩色
batch_size = 128
num_timesteps = 1000
epochs = 200 # CIFAR-10 需要更多訓練
lr = 3e-4 # 初始學習率
num_classes = 10
class_names = ['飛機', '汽車', '鳥', '貓', '鹿',
'狗', '青蛙', '馬', '船', '卡車']1.2 載入 CIFAR-10 資料集
50,000 張訓練圖片,每張 32×32 像素、三通道 RGB。注意多了一個 RandomHorizontalFlip()——隨機水平翻轉是一種資料增強,讓模型學到「汽車不管朝左朝右都是汽車」。
# ★ 資料載入(含資料增強)★
preprocess = transforms.Compose([
transforms.RandomHorizontalFlip(), # 資料增強
transforms.ToTensor(), # 轉成 [0,1] 範圍
])
dataset = torchvision.datasets.CIFAR10(
root='./data', download=True, transform=preprocess)
dataloader = DataLoader(
dataset, batch_size=128, shuffle=True,
num_workers=2, drop_last=True)看看 CIFAR-10 長什麼樣——解析度不高,但已經是有結構的自然影像了:

圖 1 — CIFAR-10 原始圖片,32×32 像素的彩色自然影像,涵蓋 10 種類別
Step 2:Cosine Noise Schedule — 更聰明的灑沙子策略
上一篇 MNIST 用的是線性 schedule——噪聲均勻地越加越多。這對灰階手寫數字沒問題,但對彩色圖片就太粗暴了。問題出在哪?線性 schedule 在早期就把太多結構資訊破壞掉了,模型很難學。
Cosine schedule[2] 的解法很優雅:讓 ᾱt 沿著餘弦曲線下降,早期加噪更慢(保留更多結構),後期才加速破壞。直覺上——先輕輕灑沙子,讓修復師有更多時間觀察細節,最後才大把灑。
# ★ Cosine Noise Schedule ★
def cosine_beta_schedule(num_timesteps, s=0.008):
steps = torch.arange(num_timesteps + 1, dtype=torch.float64)
f_t = torch.cos(((steps / num_timesteps) + s) / (1 + s)
* (math.pi / 2)) ** 2
alpha_bars = f_t / f_t[0]
betas = 1 - (alpha_bars[1:] / alpha_bars[:-1])
betas = betas.clamp(max=0.999)
return betas.float()比較兩種 schedule 的差異:
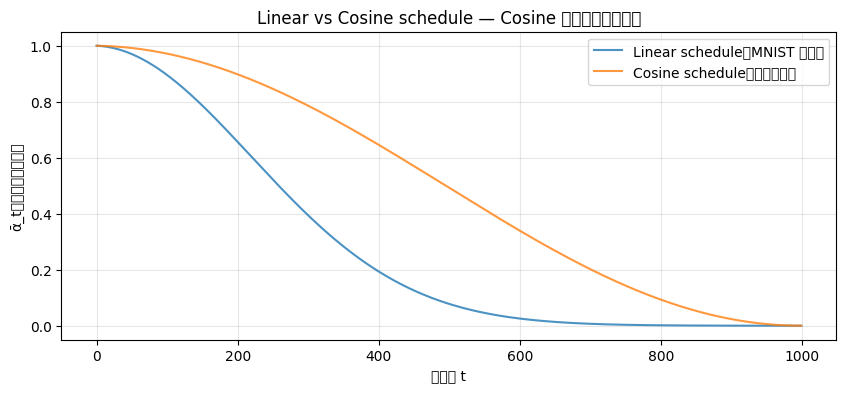
圖 2 — Linear vs Cosine schedule:Cosine 在早期保留更多原圖資訊,後期才加速衰減
看看用 Cosine schedule 加噪的效果——一匹馬逐漸消失在噪聲中:

圖 3 — 前向擴散過程(Cosine schedule):彩色圖片逐漸變成噪聲,但早期保留更多結構
Step 3:位置編碼 + Self-Attention
位置編碼和 MNIST 版本相同——用 sin/cos 波形[5]讓每個時間步 t 都有獨特的「指紋」。新增的是 Self-Attention 層。
為什麼需要 Self-Attention?MNIST 的手寫數字只需要局部特徵就能辨認——卷積核看到一撇就知道那是「7」的一部分。但 CIFAR-10 的物件有全局結構:汽車的輪子和車頂有空間關係,鳥的翅膀和身體需要整體理解。Self-Attention 讓模型的每個位置都能「看到」圖片其他位置,捕捉這種長距離依賴。
# ★ Self-Attention 層 ★
class SelfAttention(nn.Module):
def __init__(self, channels):
super().__init__()
self.norm = nn.GroupNorm(8, channels)
self.q = nn.Conv2d(channels, channels, 1)
self.k = nn.Conv2d(channels, channels, 1)
self.v = nn.Conv2d(channels, channels, 1)
self.out = nn.Conv2d(channels, channels, 1)
self.scale = channels ** -0.5
def forward(self, x):
h = self.norm(x)
B, C, H, W = h.shape
q = self.q(h).view(B, C, -1)
k = self.k(h).view(B, C, -1)
v = self.v(h).view(B, C, -1)
attn = (q.transpose(1,2) @ k) * self.scale
attn = attn.softmax(dim=-1)
out = (v @ attn.transpose(1,2)).view(B, C, H, W)
return x + self.out(out)Step 4:U-Net 模型架構(升級版)
和 MNIST 版本相比,U-Net[4] 做了五項升級——每一項都是從「能跑」到「跑得好」的關鍵:
| 升級項目 | 為什麼需要 |
|---|---|
| GroupNorm 取代 BatchNorm | BatchNorm 在小 batch 時不穩定[6],GroupNorm 不受 batch size 影響 |
| SiLU (Swish) 取代 ReLU | SiLU 是平滑的非線性函數,梯度更穩定,擴散模型普遍採用 |
| 殘差連接 | 每個 ConvBlock 內部加 shortcut,緩解深層網路的梯度消失 |
| Self-Attention | 在 16×16 解析度加入,捕捉物件的全局空間關係 |
| 條件注入 | 時間步 + 類別標籤同時注入每個 Block,讓模型知道「現在是第幾步」和「要生成什麼」 |
# ★ 升級版 ConvBlock:GroupNorm + 殘差 + 條件注入 ★
class ResConvBlock(nn.Module):
def __init__(self, in_ch, out_ch, time_embed_dim,
use_attention=False):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_ch, out_ch, 3, padding=1),
nn.GroupNorm(8, out_ch),
nn.SiLU(),
)
self.conv2 = nn.Sequential(
nn.Conv2d(out_ch, out_ch, 3, padding=1),
nn.GroupNorm(8, out_ch),
nn.SiLU(),
)
self.time_mlp = nn.Sequential(
nn.SiLU(),
nn.Linear(time_embed_dim, out_ch),
)
# 殘差連接
self.residual = nn.Conv2d(in_ch, out_ch, 1) \
if in_ch != out_ch else nn.Identity()
# 可選 Self-Attention
self.attn = SelfAttention(out_ch) \
if use_attention else nn.Identity()
def forward(self, x, t_emb):
h = self.conv1(x)
h = h + self.time_mlp(t_emb)[:, :, None, None]
h = self.conv2(h)
h = h + self.residual(x) # 殘差
h = self.attn(h) # Self-Attention
return h整體 U-Net 架構圖:
輸入(3,32,32) → [Down1: 64ch] → MaxPool
↓ skip
→ [Down2: 128ch + Attention] → MaxPool
↓ skip
→ [Bot: 256ch + Attention]
↑ skip
← [Up2: 128ch + Attention] ← Upsample
↑ skip
輸出(3,32,32) ← [Up1: 64ch] ← Upsample
+ 類別嵌入(nn.Embedding, 10→64)注入每個 BlockStep 5:Diffuser 類別(Cosine Schedule + CFG)
Diffuser 的結構和 MNIST 版本一樣——三個核心方法:加噪、去噪、完整生成。差別在於底層用了 Cosine schedule,生成時支援 Classifier-Free Guidance[3]:
# ★ CIFAR-10 Diffuser(精簡版)★
class CIFAR10Diffuser:
def __init__(self, num_timesteps=1000, device='cpu'):
self.num_timesteps = num_timesteps
self.device = device
self.betas = cosine_beta_schedule(num_timesteps).to(device)
self.alphas = (1 - self.betas).to(device)
self.alpha_bars = torch.cumprod(self.alphas, dim=0).to(device)
def add_noise(self, x_0, t):
"""前向擴散:加噪"""
T = t.long()
alpha_bar = self.alpha_bars[T].view(-1, 1, 1, 1)
noise = torch.randn_like(x_0)
x_t = torch.sqrt(alpha_bar) * x_0 \
+ torch.sqrt(1 - alpha_bar) * noise
return x_t, noise
def sample(self, model, labels, guidance_scale=3.0):
"""反向去噪:條件生成 + CFG"""
x = torch.randn(len(labels), 3, 32, 32,
device=self.device)
null_labels = torch.full_like(labels, num_classes)
for i in range(self.num_timesteps, 0, -1):
t = torch.full((len(labels),), i,
device=self.device)
# CFG: 有條件 & 無條件預測
noise_cond = model(x, t, labels)
noise_uncond = model(x, t, null_labels)
noise_pred = noise_uncond + guidance_scale \
* (noise_cond - noise_uncond)
# 去噪一步
x = self._denoise_step(x, t, noise_pred, i)
return x.clamp(0, 1).cpu().permute(0, 2, 3, 1).numpy()Step 6:訓練 200 Epochs
CIFAR-10 比 MNIST 難得多——200 個 epoch、約 78,000 個訓練步。除了更長的訓練,還多了三個穩定訓練的技巧:
- EMA(Exponential Moving Average):維護一份模型參數的「滑動平均版本」,生成時用 EMA 參數而非原始參數——像是取多次考試的平均成績,比單次考試更穩定
- Cosine Annealing 學習率:學習率從 3e-4 逐漸降到 1e-5,像開車從高速公路下匝道,先快後慢更穩當
- 梯度裁剪:防止梯度爆炸——訓練過程中如果某次更新太猛,直接剪掉,避免模型「翻車」
# ★ 初始化 ★
model = CIFAR10UNet(num_classes=num_classes).to(device)
optimizer = Adam(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer, T_max=epochs, eta_min=1e-5)
ema = EMA(model, decay=0.9999)
# ★ 訓練迴圈(精簡版)★
for epoch in range(epochs):
for x_0, labels in dataloader:
x_0, labels = x_0.to(device), labels.to(device)
# 10% 機率丟棄標籤(CFG 訓練)
mask = torch.rand(len(labels)) < 0.1
labels[mask] = num_classes # null class
t = torch.randint(1, num_timesteps+1,
(len(x_0),), device=device)
x_t, noise = diffuser.add_noise(x_0, t)
noise_pred = model(x_t, t, labels)
loss = F.mse_loss(noise_pred, noise)
optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
ema.update()
scheduler.step()6.1 訓練進度觀察
每 50 個 epoch 自動生成一次圖片,看看修復師的學習進度:

圖 4 — Epoch 50:還在亂猜,大部分是彩色噪點,完全看不出物件

圖 5 — Epoch 100:開始出現模糊的形狀,汽車和馬隱約可辨,但部分類別仍是色塊

圖 6 — Epoch 150:物件輪廓越來越清楚,馬、船、卡車已可辨識

圖 7 — Epoch 200:畢業!大部分類別都能生成辨識度高的彩色圖像
6.2 訓練損失曲線
Loss 從 0.085 快速下降到 0.033 附近,之後緩慢收斂:
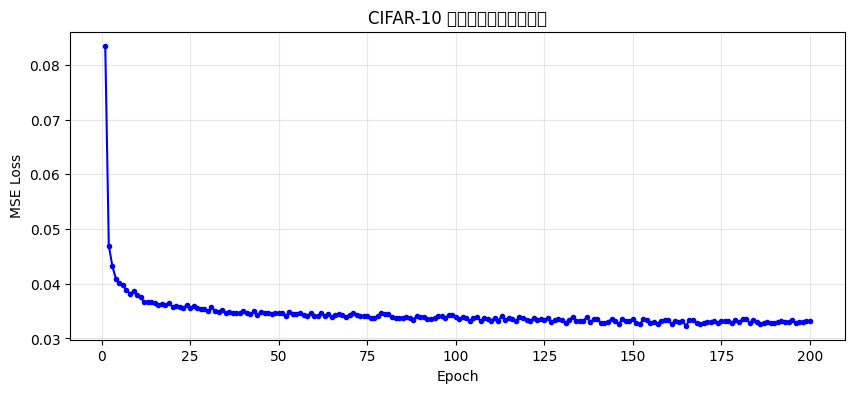
圖 8 — CIFAR-10 訓練損失曲線,200 epochs 後 Loss 穩定在 0.033 左右
Step 7:條件生成 — 指定類別生成彩色圖像!
訓練完成!用 EMA 參數 + CFG(scale=3.0)來生成 10 個類別的彩色圖像。每個類別生成 4 張:

圖 9 — 條件生成結果(CFG scale=3.0):每行一個類別,從純噪聲生成的 10 類彩色物件
雖然 32×32 的解析度不算高,但模型確實學到了每個類別的關鍵特徵——飛機有翼、汽車有輪、鳥有羽翼、馬有四足。這和 Stable Diffusion 生成 512×512 照片級圖像的原理是完全一樣的[7],差別只在模型規模和訓練資料量。
Step 8:CFG 強度比較
和 MNIST 版本一樣,CFG scale 控制模型「聽話」的程度[3]。用汽車類別做比較:
| CFG Scale | 比喻 | 效果 |
|---|---|---|
| scale = 1.0 | 輕聲說「給我一台車」 | 有車的樣子但不太穩定,偶爾跑偏 |
| scale = 3.0 | 正常說「我要汽車」 | 品質和多樣性的最佳平衡 |
| scale = 5.0 | 強調「一定要汽車!」 | 更清晰但多樣性開始下降 |
| scale = 8.0 | 大喊「只要汽車!」 | 過度飽和,出現色彩失真 |

圖 10 — CFG 強度比較:scale 越大越「聽話」,但太大會過度飽和
Step 9:觀察去噪過程
最後用慢鏡頭看看一架飛機是怎麼從純噪聲中「浮現」的:

圖 11 — 反向去噪過程:從 t=1000 的純噪聲逐步還原出一架飛機
和 MNIST 版本比較,彩色圖片的去噪更加漸進——前半段(t=1000~200)主要在建立整體結構和色調,後半段(t=200~0)才開始處理邊緣細節和紋理。這也是 Cosine schedule 的功勞:因為早期加噪更慢,模型有更多步驟可以從容地建構物件的全局形態。
總結:從玩具到生產級的關鍵升級
這次從 MNIST 到 CIFAR-10 的升級,不只是「換個資料集」——我們實際體驗了現代擴散模型的標準做法[7][8]:
| 升級 | 解決什麼問題 | 效果 |
|---|---|---|
| Cosine Schedule | 線性 schedule 太早破壞結構 | 生成品質顯著提升 |
| GroupNorm + SiLU | BatchNorm 不穩、ReLU 梯度問題 | 訓練更穩定 |
| Self-Attention | 卷積只看局部,缺乏全局理解 | 物件結構更完整 |
| 殘差連接 | 深層網路梯度消失 | 深層特徵傳遞更順暢 |
| EMA | 訓練後期參數震盪 | 生成品質更一致 |
| Cosine LR + 梯度裁剪 | 學習率太高或梯度爆炸 | 訓練過程更穩定 |
這些技術在更大的模型(如 Stable Diffusion、DALL·E)上也是標準配備。掌握了這些,你已經具備理解和改進生產級擴散模型的基礎。
🚀 立即開始實作
下載 Notebook,在 Jupyter 或 Google Colab 中跑一遍。建議用 GPU 訓練,Colab 免費 T4 大約需要 2-3 小時完成 200 epochs。
想回顧擴散模型的數學基礎?請閱讀擴散模型深度解析。還沒做過 MNIST 版本?建議先從MNIST 擴散模型實作教學開始。


