
- 本文是 CIFAR-10 擴散模型實作的進階續集——從 32×32 物件圖像升級到 64×64 真實人臉,挑戰高解析度自然影像生成
- 使用 CelebA 資料集[7]的 20 萬張名人臉部圖片,訓練無條件人臉生成器——不需要任何標籤,從純噪聲直接生成人臉
- 引入 DDIM 加速採樣[3],僅需 50 步即可生成品質接近 DDPM 1000 步的結果,速度提升 20 倍
- 實作 AMP 混合精度訓練,自動用 bfloat16 計算,記憶體減半、速度翻倍
- 附可下載 Jupyter Notebook,支援 Google Colab 一鍵運行
前情提要:為什麼要從 CIFAR-10 升級到 CelebA?
如果你已經跟著 CIFAR-10 擴散模型實作走過一遍,你已經學會了條件生成、CFG、Self-Attention 等現代擴散模型技術。但 CIFAR-10 的 32×32 解析度畢竟太低——生成出來的飛機和汽車像素感很重,離「真實感」還有一段距離。
CelebA(Celebrity Faces Attributes)[7]是一個包含超過 20 萬張名人臉部圖片的資料集。我們將圖片縮放到 64×64 像素——解析度是 CIFAR-10 的 4 倍(64×64 = 4096 像素 vs 32×32 = 1024 像素)。更重要的是,人臉是所有自然影像中最挑剔的類型——眼睛歪一點、嘴巴糊一點,人眼馬上就能察覺。
這次的挑戰升級:
| 項目 | CIFAR-10(上一篇) | CelebA(本篇) |
|---|---|---|
| 圖片尺寸 | 32×32 | 64×64(4 倍像素) |
| 資料集 | 50,000 張 | 202,599 張 |
| 主題 | 10 類物件 | 人臉(無類別) |
| 生成方式 | 條件生成 + CFG | 無條件生成 |
| U-Net 深度 | 2 層下採樣 | 3 層下採樣(64→32→16→8) |
| 採樣方法 | DDPM 1000 步 | DDIM 50 步(20× 加速) |
| 訓練精度 | FP32 | AMP bfloat16(記憶體減半) |
| Batch Size | 128 | 512(大 GPU)/ 64(T4) |
| 模型參數 | 4.6M | 5.9M |
更高的解析度意味著 U-Net 需要多一層下採樣來捕捉更細緻的特徵。同時我們引入 DDIM 來解決 1000 步採樣太慢的問題,讓生成速度提升 20 倍。
Step 1:環境設定 & 下載 CelebA
1.1 匯入套件 & 超參數
這次多了幾個新朋友:datasets(用 HuggingFace 下載 CelebA)、torch.amp(混合精度訓練)。Notebook 自動偵測 GPU 記憶體,智能選擇訓練配置:
import math, time, torch
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader, Dataset
from torch.optim import Adam
import torch.nn.functional as F
from torch import nn
from tqdm import tqdm
from torchvision import transforms
from torch.amp import autocast, GradScaler
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# ★ 超參數(自動偵測 GPU 等級)★
img_size = 64 # CelebA: 64×64
img_channels = 3 # RGB 彩色
num_timesteps = 1000
# 大 GPU (>=40GB): batch_size=512, channels=(128,256,512)
# 小 GPU (T4 16GB): batch_size=64, channels=(64,128,256)
training_mode = "fast" # fast/standard/full💡 GPU 建議:本 Notebook 針對大 GPU(A100 80GB)優化,batch_size=512。如果使用 Colab 免費 T4(16GB),會自動切換到 batch_size=64,訓練時間約 3-4 小時(fast 模式 100 epochs)。
1.2 下載 CelebA 資料集
我們使用 HuggingFace 的 datasets 庫來下載 CelebA——比 torchvision 版本更穩定(torchvision 的 CelebA 經常因為 Google Drive 流量限制而下載失敗)。
from datasets import load_dataset
hf_dataset = load_dataset('nielsr/CelebA-faces', split='train')
print(f'下載完成!共 {len(hf_dataset)} 張人臉圖片')
# → 下載完成!共 202599 張人臉圖片包裝成 PyTorch Dataset,加上資料增強:
class CelebADataset(Dataset):
def __init__(self, hf_dataset, transform=None):
self.dataset = hf_dataset
self.transform = transform
def __getitem__(self, idx):
image = self.dataset[idx]['image'].convert('RGB')
if self.transform:
image = self.transform(image)
return image
preprocess = transforms.Compose([
transforms.Resize(img_size),
transforms.CenterCrop(img_size),
transforms.RandomHorizontalFlip(), # 資料增強
transforms.ToTensor(),
])看看 CelebA 長什麼樣——64×64 的名人臉孔,五官清晰可辨:

圖 1 — CelebA 原始圖片,64×64 像素的名人臉部照片
Step 2:Cosine Noise Schedule + 前向擴散
和 CIFAR-10 一樣使用 Cosine schedule[2]——讓噪聲沿餘弦曲線漸進加入,早期保留更多臉部結構,後期才大幅破壞。
def cosine_beta_schedule(num_timesteps, s=0.008):
"""Cosine schedule — alpha_bar 沿 cosine 曲線下降"""
steps = torch.arange(num_timesteps + 1, dtype=torch.float64)
f_t = torch.cos(((steps / num_timesteps) + s)
/ (1 + s) * (math.pi / 2)) ** 2
alpha_bars = f_t / f_t[0]
betas = 1 - (alpha_bars[1:] / alpha_bars[:-1])
return betas.clamp(max=0.999).float()看看一張人臉如何逐漸變成純噪聲:

圖 2 — 前向擴散過程(Cosine schedule):人臉在 t=200 時輪廓仍可辨,到 t=600 後逐漸消失在噪聲中
Step 3:位置編碼 + Self-Attention
位置編碼用 sin/cos 波形讓每個時間步 t 擁有獨特的「指紋」。Self-Attention 讓模型捕捉人臉各部位之間的空間關係——眼睛和眉毛的對稱、嘴巴和下巴的位置。
class SelfAttention(nn.Module):
"""Self-Attention — 捕捉臉部各部位之間的空間關係"""
def __init__(self, channels):
super().__init__()
self.norm = nn.GroupNorm(8, channels)
self.attention = nn.MultiheadAttention(
channels, num_heads=4, batch_first=True)
def forward(self, x):
N, C, H, W = x.shape
h = self.norm(x)
h = h.view(N, C, H * W).permute(0, 2, 1)
attn_out, _ = self.attention(h, h, h)
attn_out = attn_out.permute(0, 2, 1).view(N, C, H, W)
return x + attn_out注意 Self-Attention 只放在 16×16 解析度——在 64×64 或 32×32 放 attention 會吃掉太多記憶體(序列長度分別是 4096 和 1024),而 16×16(序列長度 256)是效率和表達力的最佳平衡。
Step 4:U-Net 模型架構(64×64 版)
64×64 比 32×32 多了一層下採樣[4],完整路徑如下:
64×64 → [down1: 64] → 32×32
→ [down2: 128] → 16×16
→ [down3: 256 + attn] → 8×8
→ [bottleneck: 256] → 8×8
→ [up3: 256 + attn] → 16×16
→ [up2: 128] → 32×32
→ [up1: 64] → 64×64每個 ResConvBlock 包含 GroupNorm[6] + SiLU + 殘差連接 + 時間步條件注入:
class ResConvBlock(nn.Module):
"""卷積區塊:GroupNorm + SiLU + 殘差連接 + 條件注入"""
def __init__(self, in_ch, out_ch, time_embed_dim,
use_attention=False):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_ch, out_ch, 3, padding=1),
nn.GroupNorm(8, out_ch),
nn.SiLU(),
)
self.conv2 = nn.Sequential(
nn.Conv2d(out_ch, out_ch, 3, padding=1),
nn.GroupNorm(8, out_ch),
nn.SiLU(),
)
self.mlp = nn.Sequential(
nn.SiLU(),
nn.Linear(time_embed_dim, out_ch),
)
self.residual_conv = nn.Conv2d(in_ch, out_ch, 1) \
if in_ch != out_ch else nn.Identity()
self.attention = SelfAttention(out_ch) \
if use_attention else nn.Identity()
def forward(self, x, v):
h = self.conv1(x)
cond = self.mlp(v)[:, :, None, None]
h = h + cond
h = self.conv2(h)
h = h + self.residual_conv(x)
h = self.attention(h)
return h完整模型約 5.9M 參數(channels=(64, 128, 256) 配置),比 CIFAR-10 版本多了約 28%。
Step 5:Diffuser 類別 — DDPM + DDIM 雙模式
這是本篇最重要的升級:DDIM 加速採樣[3]。
DDPM 每次去噪都要跑完 1000 步——生成一張 64×64 的圖要好幾秒。DDIM 的核心想法是跳步:不需要每一步都走,等距選取 50 個時間點就夠了。直覺上——如果修復一幅畫需要 1000 次小修補,DDIM 相當於每次修大一點,只修 50 次就到位。
class CelebADiffuser:
"""Cosine schedule + DDPM/DDIM 去噪(無條件生成)"""
def ddim_sample(self, model, n_samples=16,
ddim_steps=50, eta=0.0):
"""DDIM 加速採樣 — 50 步 ≈ 1000 步品質"""
step_size = self.num_timesteps // ddim_steps
timesteps = list(range(
self.num_timesteps, 0, -step_size))
x = torch.randn(n_samples, img_channels,
img_size, img_size,
device=self.device)
with torch.no_grad():
for i in range(len(timesteps)):
t_cur = timesteps[i]
eps = model(x, t_tensor)
# DDIM:從 x_t 預測 x_0,再計算 x_{t-1}
x0_pred = (x - torch.sqrt(1 - alpha_bar)
* eps) / torch.sqrt(alpha_bar)
x0_pred = x0_pred.clamp(-1, 1)
dir_xt = torch.sqrt(
1 - alpha_bar_prev) * eps
x = torch.sqrt(alpha_bar_prev) \
* x0_pred + dir_xt
return x.clamp(0, 1).cpu()| 採樣方法 | 步數 | 生成時間 | 品質 |
|---|---|---|---|
| DDPM | 1000 步 | ~6 秒 | 基準 |
| DDIM | 50 步 | ~0.3 秒 | 接近 DDPM |
Step 6:訓練 — AMP 混合精度 + EMA
本篇引入 AMP(Automatic Mixed Precision)混合精度訓練——讓 PyTorch 自動判斷哪些運算用 bfloat16(半精度),哪些維持 float32。好處是記憶體減半、速度翻倍,精度幾乎不受影響。
# ★ 初始化 ★
model = CelebAUNet(channels=model_channels).to(device)
optimizer = Adam(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer, T_max=epochs, eta_min=1e-5)
diffuser = CelebADiffuser(num_timesteps, device=device)
ema = EMA(model, decay=0.9999)
scaler = GradScaler('cuda') # AMP 混合精度
# ★ 訓練迴圈 ★
for epoch in range(epochs):
for images in dataloader:
x = images.to(device, non_blocking=True)
t = torch.randint(1, num_timesteps + 1,
(len(x),), device=device)
x_noisy, noise = diffuser.add_noise(x, t)
# AMP:自動用 float16 計算,省記憶體 + 加速
with autocast('cuda', dtype=torch.bfloat16):
noise_pred = model(x_noisy, t)
loss = F.mse_loss(noise, noise_pred)
scaler.scale(loss).backward()
scaler.unscale_(optimizer)
nn.utils.clip_grad_norm_(
model.parameters(), max_norm=1.0)
scaler.step(optimizer)
scaler.update()
ema.update()
scheduler.step()6.1 訓練進度觀察
每 20 個 epoch 自動生成一次人臉,看看模型的學習進度:

圖 3 — Epoch 80:臉部輪廓已經成形,但細節仍然粗糙,部分人臉色調偏暗
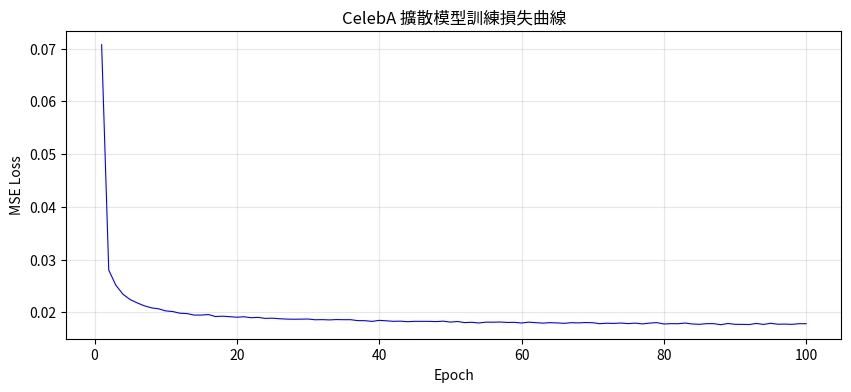
圖 4 — Epoch 100:畢業!大部分人臉五官清晰、膚色自然,已經能看出不同的髮型和表情
6.2 訓練損失曲線
Loss 從 0.07 快速下降到 0.018 附近,之後穩定收斂:

圖 5 — CelebA 擴散模型訓練損失曲線,100 epochs 後 Loss 穩定在 0.018 左右
Step 7:生成人臉!
訓練完成!用 EMA 參數 + DDIM 50 步從純噪聲生成人臉:

圖 6 — 從純噪聲生成的 16 張人臉——五官輪廓清晰,可辨識出不同的性別、髮型和膚色
生成更多張來看整體品質——32 張人臉的合集:

圖 7 — 生成的 32 張人臉合集,多樣性良好:不同的性別、年齡、髮型、膚色和表情
雖然 64×64 還不到「照片級」,但模型確實學會了人臉的整體結構:眼睛的位置對稱、鼻子在臉部中央、嘴巴在鼻子下方、頭髮的紋理和色彩——這和 Stable Diffusion 生成 512×512 人臉的原理是完全一樣的[5],差別只在模型規模、解析度和訓練資料量。
Step 8:觀察去噪過程
用慢鏡頭看看一張人臉是怎麼從純噪聲中「浮現」的——DDIM 50 步去噪過程:

圖 8 — DDIM 去噪過程(50 步):從 t=1000 的純噪聲逐步還原出一張人臉
觀察去噪的階段性:
- t=1000~600:純噪聲階段,幾乎看不出任何結構
- t=500~300:臉部整體輪廓開始浮現——頭部的橢圓形、膚色的大致色調
- t=200~100:五官定位——眼睛、鼻子、嘴巴的位置確立,髮型的輪廓成形
- t=100~0:細節精修——膚色細節、髮絲紋理、光影效果
這個過程完美對應了擴散模型的設計哲學[1]:先建立宏觀結構,再逐步添加細節——就像畫家先打草稿、再上色、最後畫精細紋理。
總結:從物件到人臉的關鍵升級
從 CIFAR-10 到 CelebA 的升級,核心不只是「換個資料集」——我們體驗了擴散模型在實際應用場景中的關鍵技術[5][8]:
| 升級 | 解決什麼問題 | 效果 |
|---|---|---|
| 64×64 解析度 | 32×32 太粗糙,看不出臉部細節 | 眼睛、嘴巴、髮型清晰可辨 |
| 三層 U-Net | 更高解析度需要更深的下採樣 | 64→32→16→8 捕捉多尺度特徵 |
| DDIM 加速 | DDPM 1000 步太慢 | 50 步即可,速度提升 20× |
| AMP 混合精度 | 大模型 + 大 batch 吃記憶體 | 記憶體減半、速度翻倍 |
| 無條件生成 | 人臉不需要類別標籤 | 架構更簡潔,專注生成品質 |
| HuggingFace datasets | Google Drive 下載不穩定 | 穩定下載 20 萬張圖片 |
這三篇 Hands-on Lab 系列——MNIST → CIFAR-10 → CelebA——完整走過了擴散模型從入門到進階的實作旅程。掌握了這些技術,你已經具備理解和改進生產級擴散模型(如 Stable Diffusion、DALL·E)的堅實基礎。
🚀 立即開始實作
下載 Notebook,在 Jupyter 或 Google Colab 中跑一遍。建議用 GPU 訓練,Colab 免費 T4 大約需要 3-4 小時完成 100 epochs(fast 模式)。
想回顧擴散模型的數學基礎?請閱讀擴散模型深度解析。還沒做過前兩篇?建議從 MNIST 擴散模型實作教學開始。


