- BCGの報告によると、GoogleとMicrosoftの新規コードの約30%がAIにより生成されており、McKinseyが600以上の組織を追跡調査したところ、高パフォーマンスチームは16-30%の生産性向上と31-45%のソフトウェア品質改善を達成しました——ただし、プロセスと組織を同時に改革した企業に限られます
- MIT Sloan Management ReviewはAI支援開発の隠れたコストを明らかにしています:重複コードブロックが8倍に増加し、コードチャーン(コード攪拌)が2倍になり、迅速な出力が実際には技術的負債の蓄積を加速させています
- Brooksの1987年の「本質的複雑性と偶発的複雑性」フレームワークは、現在のソフトウェアエンジニアリング変革に対する最も正確な分析レンズを提供しています:生成AIは偶発的複雑性を劇的に排除していますが、本質的複雑性——要件理解、アーキテクチャ判断、ドメインモデリング——は依然として深い人間の専門知識を必要とします
- 私たちの実践では、チームのナレッジを機械可読形式(Markdownドキュメント、AIスキル定義)に体系的に構造化することで、AIツールがすべての実行においてベストプラクティスに自動的に従うようになり、持続的にイテレーション可能な「組織インテリジェンスインフラ」を形成することが示されています
1. ソフトウェアエンジニアリングは方法論レベルの変革を迎えている
学問分野としてのソフトウェアエンジニアリングは、過去半世紀にわたっていくつかの根本的な方法論的転換を経験してきました。Dijkstraが1968年に発表した「Go To文は有害である」[1]が構造化プログラミング革命を起こして以来、オブジェクト指向プログラミング、アジャイル開発、クラウドネイティブアーキテクチャに至るまで、各変革は「優れたソフトウェアはどのように構築されるべきか」を再定義してきました。
2025年から2026年にかけて、私たちはさらなる方法論的変革の転換点に立っています。BCGの研究[2]は、GoogleとMicrosoftの新規コードの約30%がすでにAIにより生成されており、既存のAI支援コーディングツールは30-50%の開発生産性向上を実現していることを示しています。Stanford AI Index 2025レポート[3]は驚異的な進歩を記録しました:SWE-bench(実際のGitHubソフトウェアエンジニアリング問題に基づくベンチマーク)において、AIシステムの解答率は2023年の4.4%から2024年の71.7%に飛躍的に向上し、わずか1年で67.3パーセントポイントの上昇を遂げました。
しかし、これらの数字は物語の片面しか語っていません。真に重要な問いは「AIはコードを書けるか」ではなく、むしろ:AIがコード生成作業のますます大きな割合を担うようになったとき、ソフトウェアエンジニアリングの方法論、チーム構造、アーキテクチャ判断はどのように調整されるべきなのか?ということです。
2. Brooksのフレームワークの現代的意義:本質的複雑性と偶発的複雑性
AIがソフトウェアエンジニアリングに与える影響を体系的に理解するために、Frederick Brooksの1987年の論文「銀の弾丸はない」[4]は依然として最も説明力のある分析フレームワークです。Brooksはソフトウェア開発における2種類の複雑性を区別しました:
- 本質的複雑性:問題ドメイン自体から生じるもの——要件分析、システムアーキテクチャ設計、ドメインモデリング、境界条件の定義。この複雑性はより良いツールによって排除することはできません。なぜなら、問題自体の固有の特性だからです
- 偶発的複雑性:ツール、プロセス、技術的制約から生じるもの——構文の詳細、ボイラープレートコード、ビルド設定、デプロイメントワークフロー、環境管理。この複雑性は現在の技術条件の産物であり、理論的にはより良いツールによって排除可能です
このフレームワークを通じて見ると、生成AIの価値提案は明確になります:ソフトウェア開発における偶発的複雑性を体系的に排除しているのです。コード生成、ドキュメント作成、テスト作成、ボイラープレートコード——これらの従来膨大な開発者の時間を消費していたタスクは、本質的に偶発的複雑性の領域にあります。McKinseyの研究[5]はこれを確認しました:生成AIの時間節約効果はコードドキュメント作成で最も顕著(半減)、次いで新規コード作成、そしてコード最適化の順でした。タスクが「偶発的複雑性」に近いほど、AIの加速効果はより顕著です。
しかし、Brooksのフレームワークは同時に警告も発しています:本質的複雑性はツールの改善によって消滅しません。要件が正しく理解されているか、アーキテクチャが問題のスケールに適合しているか、システム境界が適切に定義されているか——これらの判断は依然として深いドメイン専門知識とエンジニアリング経験を必要とします。
3. 生産性のパラドックス:速度向上の裏に潜むコスト
MIT Sloan Management Reviewの2025年の重要な研究[6]は、すべての技術的意思決定者が注目すべき現象を明らかにしています:AI支援開発の生産性向上にはコストが伴います。
この研究はGitClearの2020年から2024年にわたる数百万行のコード分析を引用し、2つの憂慮すべきトレンドを明らかにしました:重複コードブロックが8倍に増加し、コードチャーン(書かれた直後に修正または削除されるコードの割合)が2倍になりました。言い換えれば、開発者は確かに速く書いていますが、修正または破棄が必要なコードもより頻繁に書いているのです。
BCGの研究[7]はさらに、80%以上の企業が生成AIをコーディングワークフローに統合している一方、75%以上の開発者導入率を達成したのはわずか20%であり、CIOの50%がAIのエンジニアリング効果への実際のインパクトを定量化できないと認めていることを発見しました。さらに重要なのは:旧式のシステムアーキテクチャと未成熟なDevOpsプラクティスがAIツールの効果を大幅に低下させているということです——つまり、AIは銀の弾丸ではなく、価値を届けるためにはモダンなエンジニアリングプラクティスと連携して機能する必要があります。
McKinseyが600以上の組織を追跡した研究[8]は、より完全な全体像を提示しています:最もパフォーマンスの高いAI導入組織は確かに16-30%のチーム生産性向上と31-45%のソフトウェア品質改善を達成しました。しかし、これらの組織に共通する特徴は、ツールを導入しただけでなく、同時にプロセス、役割定義、仕事の仕方を包括的に改革したことです。方法論を変えずにツールだけを導入した組織は、ほとんど改善が見られませんでした。
4. R&Dチームの役割の構造的シフト
ハーバードビジネススクールの実証研究[9]は、労働市場データを通じてAIがソフトウェア開発の労働力構造に与える影響を明らかにしています:高度に自動化可能な構造的認知タスクを含むポジションは17%減少した一方、AIが補完ツールとして機能するポジションは実際に22%増加しました。注目すべきは、エントリーレベルのソフトウェア開発者の求人がトレンドより4.7パーセントポイント低いことです——これはレイオフによるものではなく、企業が新規採用を減らしたことによるものです。
これらのデータは構造的シフトを示しています:開発者の中核的価値は「コードを生産する」ことから「コードの正確性と適切性を判断する」ことへとシフトしています。ACM Transactions on Software Engineering and Methodologyの2025年サーベイ論文[10]は、このシフトをソフトウェアエンジニアリングの学問レベルの再定義として位置づけています——要件分析からコード生成、テスト、メンテナンスに至るまで、AIは開発ライフサイクル全体に浸透しており、人間の役割はより高次の設計判断と品質保証に移行しています。
R&Dチームマネージャーにとって、これは3つの具体的な調整領域を意味します:
- 能力モデルの再構築:採用とトレーニングの優先事項を「正しいコードを書く能力」から「AI生成コードが正確で、安全で、アーキテクチャ基準に準拠しているかを判断する能力」にシフトする必要があります
- レビュープロセスの強化:大量のコードがAI生成される場合、コードレビューはもはやオプションではなく中核的な生産活動となり、より多くのシニアエンジニアの時間投資が必要です
- アーキテクチャガバナンスのアップグレード:AIは迅速にコードを生成できますが、アーキテクチャレベルのトレードオフを自律的に行うことはできません——これには明確なアーキテクチャガイドラインと意思決定メカニズムが必要です
5. アーキテクチャ判断の再考:不必要な偶発的複雑性の排除
AIがソフトウェア開発に与える影響は、「より速いコード記述」のレベルにとどまるべきではありません。より深い洞察は、これまで当然視されてきた多くのアーキテクチャ判断を再検討することを私たちに強いるということです。
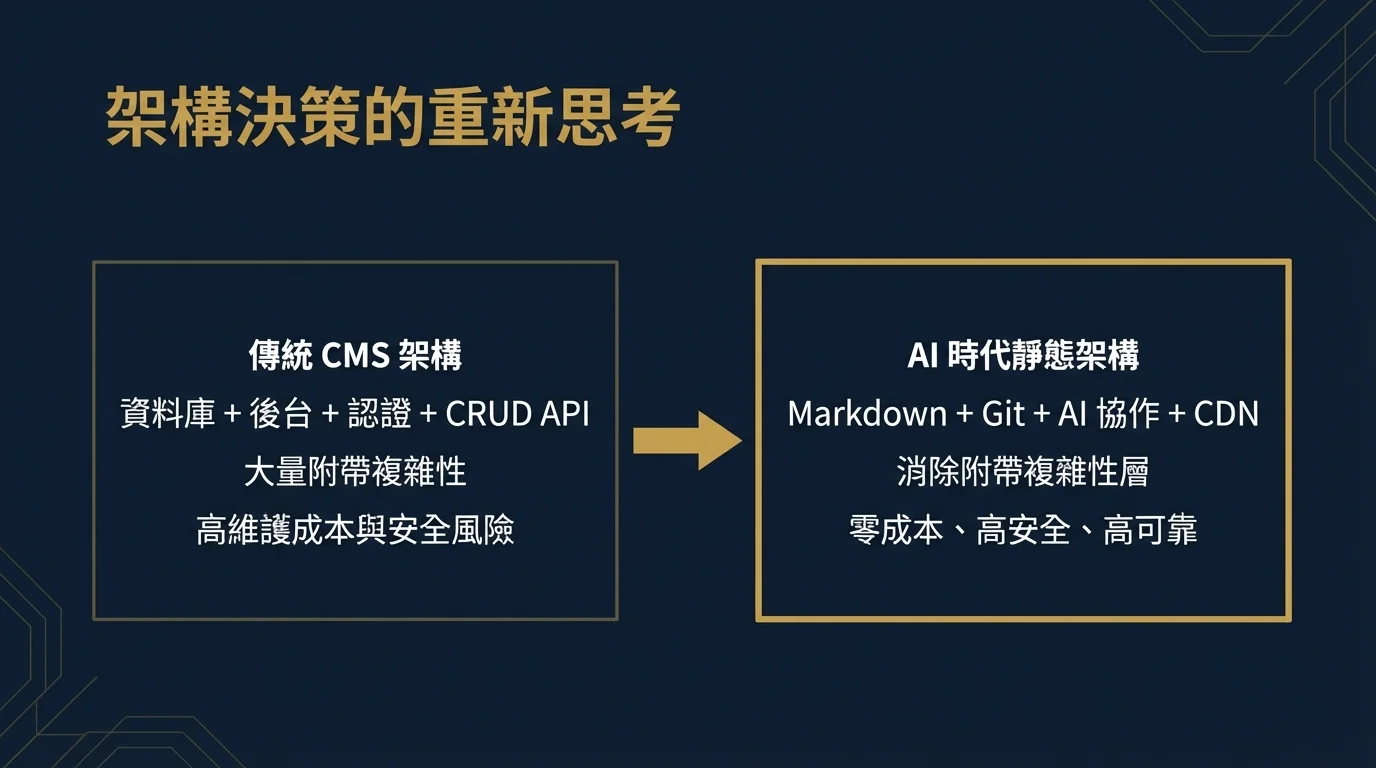
コンテンツ管理を例に取りましょう。従来のウェブサイトコンテンツ公開はほぼ例外なくフルCMSバックエンドシステムに依存していました:データベース設計、ユーザー認証、CRUD API、管理インターフェース、画像アップロードとストレージ、サーバーメンテナンス。これらのコンポーネントの構築とメンテナンスは重大なエンジニアリングオーバーヘッドを構成し——それらはすべてBrooksが「偶発的複雑性」と呼んだものに該当します:「高品質なコンテンツを公開する」という本質的な目標とは無関係でありながら、相当な開発・運用リソースを消費します。
AI支援開発の文脈では、根本的に異なるアーキテクチャが可能になります:構造化されたMarkdownファイルを使用した静的サイトジェネレーター、コンテンツ作成、メタデータ生成、画像作成のためのAIコラボレーション、コンテンツ変更を管理するバージョン管理(Git)、自動デプロイメントを処理するCDN(Cloudflare Pagesなど)。このアーキテクチャは、データベース、バックエンド、認証システムを含むすべての偶発的複雑性レイヤーを排除しつつ、より高いセキュリティ(攻撃対象となるバックエンドがない)、より低い運用コスト(静的リソースはほぼゼロコスト)、より良い信頼性(データベースダウンタイムリスクがない)を獲得します。
これは手抜きではなく、AI時代における合理的なアーキテクチャ判断です。生成AIがコンテンツフォーマット、メタデータ生成などの構造的作業を効率的に処理できるとき、これらのタスクのために特別に構築されたバックエンドシステムは不必要な偶発的複雑性となります。コンパイラの出現がアセンブリ言語の手書きを不必要な偶発的作業にしたように、AIの成熟は多くの以前は「必要」だったアーキテクチャレイヤーを時代遅れにします。
6. 組織ナレッジの構造化された体系化:新しいタイプの知的資産
私たちが実践で観察したもう一つの重要なトレンドは、チームが企業ナレッジを管理する方法の根本的な変化です。
従来のソフトウェアエンジニアリングのナレッジマネジメントは、ドキュメント(Wiki、Confluence)、コードコメント、口承伝達、コードレビューを通じた経験移転に依存していました。これらの方法に共通する限界は、ナレッジの消費者が人間であり、人間の読解、理解、適用にはすべてロスが伴うことです。完璧なコーディング基準ドキュメントが作成されても二度と読まれず、同じ種類の問題がコードレビューで繰り返し指摘されるのは、ナレッジ移転の非効率さを示しています。
AI支援開発ワークフローでは、新しい可能性が生まれます:組織ナレッジをAIが直接消費できる形式に構造化すること。
具体的には、私たちのチームは開発標準、アーキテクチャ決定記録、よくある落とし穴、品質基準などの経験を、構造化されたMarkdownドキュメントまたはAIスキル定義(Skills)に体系的に整理しています。AIツールがタスクを実行する際、これらのドキュメントはコンテキストとして自動的にロードされ、AIがすべてのコード生成においてチームのベストプラクティスに従うことを可能にします——開発者がドキュメントを記憶したり参照したりすることに依存することなく。
これは本質的に新しいタイプの「組織インテリジェンスインフラ」です:
- ゼロロス移転:AIは構造化されたドキュメントを読み、即座に適用します。人間の読解理解に固有の減衰がありません
- 一貫した品質:シニアエンジニアでも新入チームメンバーでもAIツールを使用する場合、出力は同じ品質基準に従います
- イテレーティブな進化:新しいベストプラクティスや落とし穴が発見されるたびに、ドキュメントを更新すれば、すべての後続の出力に即座に反映されます
このコンセプトをさらに深めると:AI時代において、R&Dチームの最も価値のある資産は、メンバーの技術力だけでなく、構造的に体系化された集合的判断とドメイン経験です。人は異動し、記憶は薄れますが、適切に構造化されたナレッジドキュメントにより、AIツールはチームの最高レベルのパフォーマンスを一貫して発揮できます。
7. テクノロジー意思決定者への体系的な推奨
上記の分析と私たちの実践経験に基づき、AI時代のR&D戦略を計画しているテクノロジー意思決定者に以下の推奨を提供します:
7.1 Brooksのフレームワークを使用して既存アーキテクチャを監査する
既存の技術アーキテクチャを体系的にレビューし、本質的複雑性と偶発的複雑性を区別します。偶発的複雑性が高い領域(ボイラープレートコード、ビルド設定、コンテンツ管理バックエンド、反復的なCRUDレイヤー)については、AI支援やアーキテクチャの簡素化により排除できるかどうかを評価します。MIT Sloanの研究[6]は、ブラウンフィールド(レガシーシステム)環境では、AI生成コードが既存の問題を悪化させる可能性があることを注意喚起しています。したがって、アーキテクチャの簡素化はAIツール導入に先行すべきです。
7.2 プロセスと役割定義を同時に改革する
McKinseyのデータ[8]は、ツールのみを導入して仕事の仕方を変えない組織はほとんど改善が見られないことを明確に示しています。AIツールの導入には、コードレビュープロセスの強化、開発者能力モデルの調整、アーキテクチャガバナンスメカニズムの確立が伴うべきです。シニアエンジニアの時間は「コードを書く」ことから「コードをレビューする」ことと「アーキテクチャガイドラインを定義する」ことに再配分されるべきです。
7.3 ナレッジの構造化に投資する
チームのコーディング基準、アーキテクチャ決定記録(ADR)、一般的なエラーパターン、品質基準を構造化されたドキュメントに体系的に変換します。これはAI時代において最も高いAI ROIをもたらすエンジニアリング投資の一つです——AIツールの出力品質を向上させるだけでなく、組織にとって持続的に進化する知的資産を構築します。
7.4 定量的な技術的負債モニタリングを確立する
AI支援開発が技術的負債の蓄積を加速させる可能性がある[6]ことを考慮すると、定量的なコード品質モニタリングメカニズムの確立が極めて重要です。重複率、チャーン率、複雑度指標などの主要メトリクスを追跡し、開発速度の向上が長期的なメンテナンスコストの犠牲の上に成り立っていないことを確認します。
8. まとめ:ツールの置き換えではなく、方法論の変革
約40年前のBrooksの洞察に立ち返ると:ソフトウェアエンジニアリングの根本的な課題はツールにあるのではなく、問題自体の複雑性にあります。生成AIは前例のない速度で偶発的複雑性を排除している強力なツールですが、本質的複雑性——要件の理解、アーキテクチャの設計、正しいエンジニアリング判断——は依然として人間にとって代替不可能な領域です。
真に重要なのは「コーディングにAIを使うかどうか」ではなく、企業がAIの支援のもとでアーキテクチャ判断を再検討し、チームの役割を再定義し、ナレッジマネジメントのアプローチを再考する能力を持っているかどうかです。AIを単に「より速いタイピスト」と見なす組織は、最終的にこれが方法論の変革であることを理解する組織に追い越されるでしょう。
あなたのR&DチームがどのようにしてシステマティックにAIツールを統合し、開発プロセスを再構築し、組織ナレッジインフラを構築するかを評価しているなら、私たちのチームは学術研究からエンジニアリング実装まで完全な経験を有しており、深い技術的対話を歓迎します。
プレゼンテーションスライド